On August 19th, Dr. Alexander Gray, CTO and Co-Founder, Skytree, and Cindy Maike, General Manager, Insurance at Hortonworks, will be joining Patricia Harman, Editor-in-Chief at Claims Magazine, for a Skytree webinar on “Driving profitability and lowering costs using Machine Learning on Hadoop.”
Register for the Webinar on August 19th at 10am Pacific/1pm Eastern time
In this blog, Alex and Cindy exchange perspectives on what machine learning means for insurers, and where opportunities are for its application. Please join Claims Magazine, Skytree and Hortonworks on August 19th for more on this exciting topic.
1. Why is machine learning (ML) of interest to the insurance industry?
[Cindy Maike] – The insurance industry is founded on forecasting future events and estimating the value/impact of those events and has used established predictive modeling practices – especially in claims loss prediction and pricing – for some time now. This kind of modeling has been founded largely on statistical modeling methods (e.g. GLM). With big data and new data sources such as sensors/telematics, external data sources (Data.gov), digital (interactions), social and Web (sentiment), the opportunity to apply ML techniques has never been greater across new areas of insurance operations.
[Alexander Gray] – Machine learning is the modern science of finding patterns in your data in an automated manner using sophisticated methods and algorithms. The traditional usage of statistics in the insurance industry to create predictive models compromises the accuracy of the models created in part because it relies on sampled data. In addition, the methods/algorithms used to create these models are rudimentary at best. Machine learning has the promise of being able to analyze ALL of the available data using complex methods/algorithms, resulting in more accuracy, and directly impacting the bottom line for insurance companies. The challenge, therefore, is to create a solution that can store large troves of relevant data along with a machine-learning platform that can analyze ALL of the data in a timeframe that is acceptable.
2. What specific areas within the insurance industry do you see ML and big data solutions driving high-value?
[Alexander Gray] – As Cindy mentioned, we are seeing lots of demand from insurers. The use cases fall into six broad categories, and each of these can impact premiums or an insurance company’s loss ratio.
1) Fraud mitigation. Perhaps one of the biggest areas where we see insurers applying machine learning on big data to improve their P&L is by mitigating application and premium fraud, underwriting risk, and driving down premium leakage – all enormous expense line items.
2) Claims management. Another big area where we see insurers using machine learning to drive down costs is in the area of claims: audit, leakage, predictions, severity, mitigation and subrogation on the P&C side. Machine learning on Hadoop is great for claims because a large amount of the data is unstructured.
3) Marketing. Insurance marketing executives are using machine learning to manage customer churn and to improve the customer experience by way of offering relevant products and solving problems faster. Also important – especially to insurers with a direct channel – is the use of ML to evaluate marketing and advertising effectiveness.
4) Finance. Insurance CFOs and other finance executives can use machine learning for loss modeling, policy profitability analysis, loss adjustment expense (LAE) modeling and litigation.
5) Telematics. Another area with an increased interest and application of ML is telematics information and learning from driver behavior (where customers have opted in to share their data). The telematics data is analyzed with other data sources such as weather, road conditions, geo-location and speed limits.
6) Case management and population health. Using machine learning here is especially helpful for insurers with strong incentives to improve outcomes, as is the case of health insurance plans launched from existing medical systems.
3. How does one become “machine-learning ready” on Hadoop?
[Cindy Maike] – Recommendations I give insurance customers are:
- Don’t boil the ocean – pick an initial problem area and understand that the first use case you choose won’t solve every analytical challenge you have out of the gate. It is a learning process.
- Building on “don’t boil the ocean,” make sure you choose the right insurance business process that makes sense to leverage ML. What I mean is – is it a relatively mature and stable process?
- Understanding your data is KEY. Where is the data being sourced from that will reside in Hadoop, and how is it used for business decisions today? Also, ask if there are new data sources you can leverage to better understand and learn from your problem.
- Be clear on what “outcome” you are striving to achieve. If you are crisp on the definition of a successful outcome, you will have a higher probability of achieving your goals to generate valuable and actionable insights.
[Alexander Gray] –
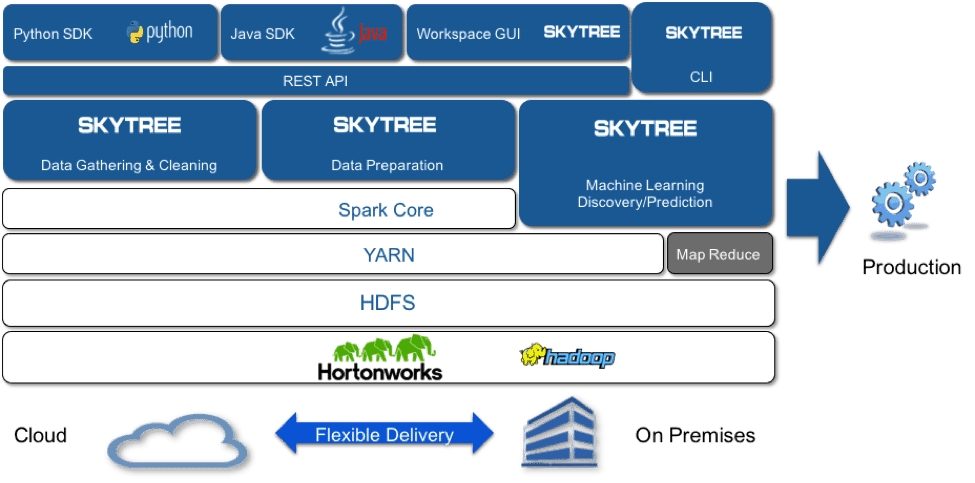
- We recommend using a unified machine-learning platform to do all of your machine-learning tasks. The complex nature of the data makes the data preparation, fusion, and machine learning modeling non-standard and non-trivial. Most big-data tools do not contain the advanced machine-learning techniques necessary to deal with the special data modalities represented by free text and temporal event data, let alone fuse them and perform modeling using them. Skytree’s unified data science platform uniquely addresses this need, taking advantage of the consolidation of data into Hadoop.
- Partner with leading vendors with expertise in your domain. The complexity of both the big data infrastructure and the machine-learning tools required can be daunting. Hortonworks’ professional services and support help clients to navigate the infrastructure complexity. Skytree’s first-of-a-kind automation mechanizes key elements of the data science required to create such models, often allowing even non-experts to create state-of-the-art machine-learning models and generate valuable insights such as high risk claims
4. Do you need to be a specific size or type of insurance company to leverage ML on Hadoop to obtain a positive ROI?
[Cindy Maike] – We see insurance companies of all sizes and lines of business leveraging Hadoop. In general, there is more focus on variety, veracity, velocity, visualization and value – vs. volume. The volume element is important for some, but definitely not all insurers. ML is important for insurance companies wanting to better understand and learn from their data vs. relying on traditional sampling of data for statistical analysis.
[Alexander Gray] – There are several potential issues to be aware of as an insurer works to incorporate machine learning into their operations:
- Potential data science skills gap on team. In this case, utilize tools that incorporate high levels of automation.
- The ability to handle unstructured data. This requires specific data preparation capabilities to be able to manage and include the wide variety of unstructured data types and formats.
- Getting value from your data requires high predictive accuracy via powerful machine-learning methods.
- Imperfect data in a client’s dataset requires ways to treat rare event data, missing values, etc.
5. Tell me a little bit about how Skytree and Hortonworks are working together on this?
[Cindy Maike] – Skytree and Hortonworks bring together the insurance industry’s traditional data and big data sources and leverage the power of the data lake on Hadoop to optimize predictive analytics with ML capabilities. Insurance companies can build upon predictive modeling and expand with ML on new data sources at a greater scale in high-impact areas marketing, telematics, IoT, loss control and claims fraud/leakage. This analysis can identify new revenue streams and opportunities to better predict and manage expenses.
[Alexander Gray] – Skytree’s machine-learning platform is HDP certified and YARN Ready, and runs natively on the latest version of HDP, providing greater integration between Machine Learning on YARN and Spark, and enabling top insurance companies to address core problems such as loss, bind and retention modeling, ultimately leading to premium pricing optimization. Today, only a subset of all insurance-related data is utilized in predictive modeling, which compromises the model accuracy, leading to massive, non-ignorable losses. Skytree’s machine-learning platform magnifies the ability of a small number of auditors to “compress” their knowledge into a predictive model that can be applied much earlier in workflow of the insurance industry, resulting in more accuracy, and directly impacting the bottom line for insurance companies.
Learn More:
- Register for the Webinar on August 19th at 10am Pacific/1pm Eastern time
- Visit the Skytree-Hortonworks parter page and Skytree website.
The post Driving profitability and lowering costs using Machine Learning on Hadoop appeared first on Hortonworks.